

Introduction
Graphical user interfaces do not translate directly to screenless environments, often causing severe cognitive overload and high abandonment rates during transient interactions. Legacy text-based workflows fail entirely when forced to handle the asynchronous complexity of human speech. To resolve this, engineering teams must deploy state-based intent architectures paired with explicit conversational design patterns for modern voice user interfaces (VUIs). By replacing open-ended queries with directed parameters and implementing multimodal fallbacks, engineers can construct robust, context-aware frameworks. Implementing these structured workflows directly minimises API latency, lowers cloud compute costs, and ensures strict adherence to regional compliance standards.
The Context / The Problem
Why is this a challenge right now? Voice user interfaces are scaling rapidly, with the global voice commerce sector projected to process nearly €80 billion by 2035 [market growth analysis]. Despite this growth, traditional development approaches fail in audio-first environments because visual and voice modalities possess fundamentally different cognitive constraints.
Visual interfaces allow users to browse safely and visually confirm system status before executing commands. Voice interactions, however, are highly transient and demand significant short-term memory.
Real-world constraints frequently compound these issues. Legacy manufacturing systems often cannot handle the throughput required for real-time analytics, and basic voice systems similarly fail when pushed beyond simple, isolated commands. Users operating heavy machinery, driving vehicles, or executing manual tasks cannot safely monitor visual screens. Relying on open-ended prompts under these environmental constraints leads directly to system failure, higher cloud latency due to repeated query processing, and severe user frustration.
The Technical Deep-Dive / Architecture
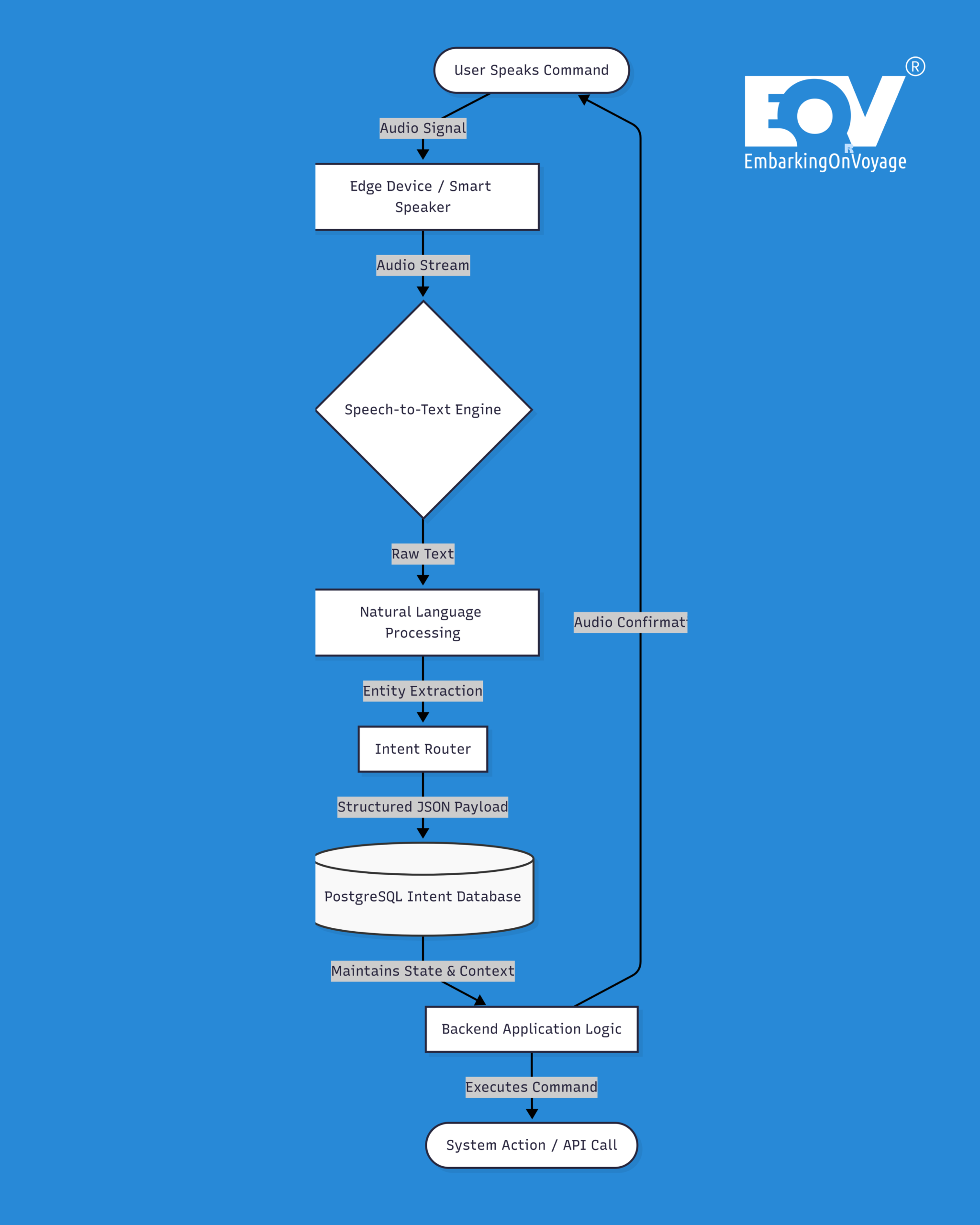
Architecting Context and Memory The foundation of a production-ready VUI involves managing conversational state and retaining contextual memory across multiple interactions. If a user requests climate metrics (e.g., measuring room temperature in Celsius), the natural language understanding model must lock that context for subsequent queries.
We chose PostgreSQL over MongoDB here because strict ACID compliance was non-negotiable for this financial data. Tracking persistent state for secure voice-activated commerce requires a system that guarantees atomicity and durability, ensuring transactions never fail silently. A structured database architecture ensures that all conversational parameters are accurately mapped and retained securely over time.
Defining Explicit Parameters
To eliminate open-ended prompts and reduce unnecessary cloud latency, engineering teams must enforce implicit confirmations and strict intent routing. Open queries must be replaced with explicitly defined state payloads.
Below is a standard JSON payload demonstrating how parameters are strictly defined to constrain user inputs and reduce speech recognition errors:
{
"intent": "AdjustThermostat",
"parameters": {
"target_temperature": 22,
"unit": "Celsius"
},
"context": {
"userId": "usr_8492",
"lifespan": 5
},
"error_handling": {
// Fallback message explicitly defines options so junior engineers can quickly follow the error recovery logic
"fallback_message": "Did you want to set the temperature to 20 or 22 degrees?"
}
}By constraining the user’s available choices through explicit error handling, the system natively handles edge cases without dropping the session or requiring costly cloud-side reprocessing.
| Interaction Type | Cloud Latency Impact | User Cognitive Load | Error Recovery |
| Open-Ended VUI | High (Requires heavy NLP processing) | High (Requires memorisation) | Poor (“I didn’t understand”) |
| State-Based VUI | Low (Pre-defined JSON parameters) | Low (Explicit choices offered) | High (Contextual prompting) |
Multimodal Audio Redundancy
Relying solely on audio introduces latency uncertainty. Modern voice systems must integrate multimodal redundancies to ensure clear system status. When a microphone activates, the hardware should immediately output a brief audio tone paired with an LED indicator pulse. This deliberate redundancy ensures the user visually understands the device’s operational state without needing explicit, time-consuming verbal confirmations.
Security & Compliance Considerations
Data Privacy in Voice Processing Continuous audio recording mechanisms introduce severe surveillance and compliance risks. Voice user interfaces deployed within the European Union must be engineered strictly around consent and robust security parameters. Implementing Zero-Trust principles across the entire data transmission pipeline is an absolute requirement.
To maintain rigorous GDPR compliance, raw audio inputs must be processed on-device via edge computing wherever technically feasible. Furthermore, enforcing Tech Sovereignty through rigid data localisation policies prevents sensitive user telemetry from leaving designated European cloud environments. Teams must explicitly define Data Lineage models to map exactly where user recordings are stored, how they are routed, and when they are definitively anonymised.
The Bottom Line
- Deploy state-based intent architectures: Eliminate open-ended conversational prompts and implement constrained, context-aware database mapping to lower cognitive overhead and reduce cloud latency.
- Implement multimodal redundancy: Synchronise audio confirmations with visual hardware cues to clearly communicate system state and prevent privacy anxieties.
- Enforce strict European compliance standards: Default to edge computing and rigid data localisation to guarantee GDPR compliance, Zero-Trust security, and absolute Tech Sovereignty for all voice user interfaces.
Transitioning from graphical legacy applications to secure, conversational architectures requires highly specialised engineering capabilities. EmbarkingOnVoyage builds these solutions for enterprise partners, delivering highly compliant, robust voice platforms that ensure operational efficiency and tangible business outcomes.
Latest Blog highlight : https://embarkingonvoyage.com/blog/physical-ai-industry-4-0-europe/
Leave a Reply