AI hallucinations in Indian enterprises are becoming a critical boardroom concern, even as “Embrace AI” remains the defining corporate message of this decade. From rapid digital startups to large-scale operational hubs across the country, AI has transformed how organizations build products, automate marketing calendars, and make data-driven decisions. It is an undeniable force multiplier for productivity.
Yet, AI is not infallible. Large Language Models can hallucinate, autonomous agents can execute incorrect workflows, and models can drift as business conditions evolve. The issue is not whether AI will fail – it inevitably will at times. The real question is whether your enterprise architecture is prepared for AI hallucinations in Indian enterprises when those failures happen.
The Reality of AI Hallucinations in Indian Enterprises
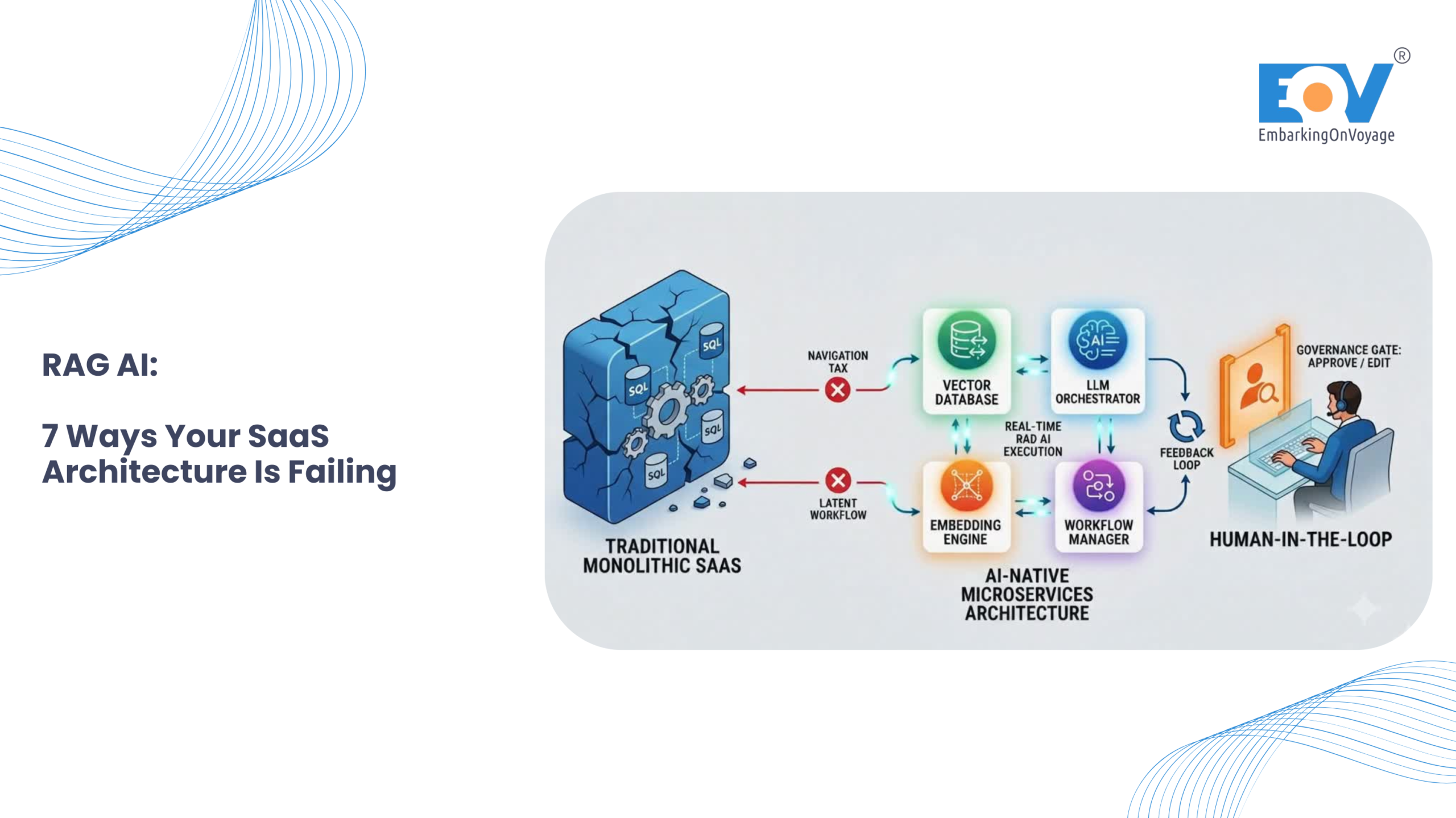
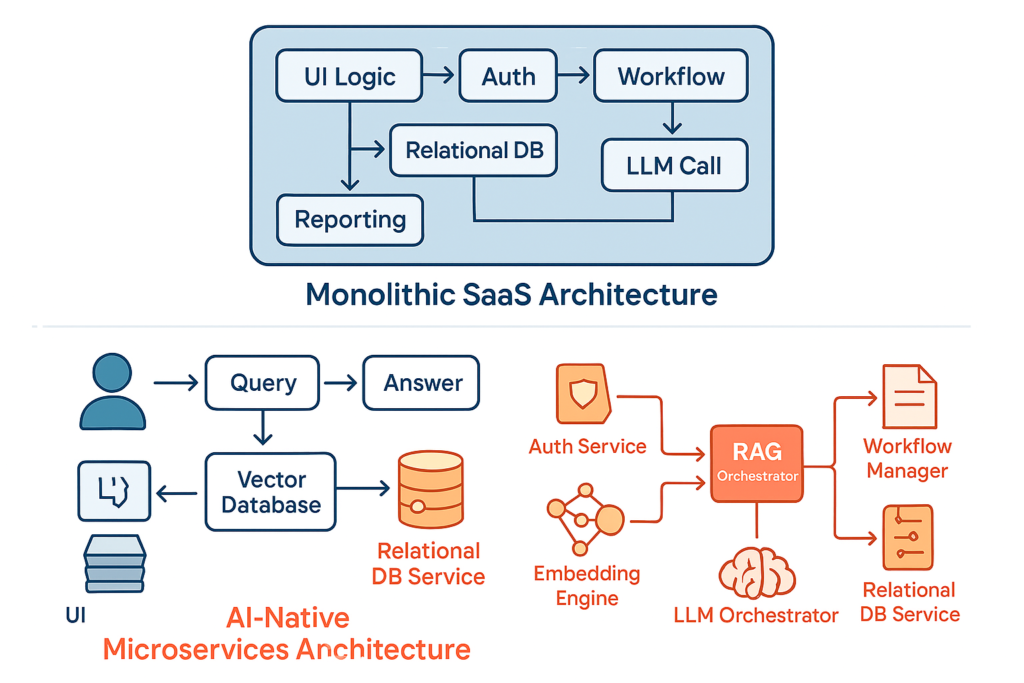
Too many organizations treat AI as the final destination rather than a capability within a broader enterprise architecture. Just as marketing leaders and IT teams design resilient cloud infrastructure with redundancy, failover mechanisms, and disaster recovery, AI systems require the exact same resilience.
Consider the stakes in high-volume digital marketplaces, telecom, or fintech environments. If an AI chatbot hallucinates a regulatory policy or a pricing structure, the brand reputation and compliance risks are immediate. As teams launch comprehensive corporate website overhauls or deploy centralized bug-tracking registries, integrating AI without a safety net can turn a digital transformation into a liability. Proactively managing AI hallucinations in Indian enterprises is no longer optional; it is a core operational requirement.
The 4 Pillars of Enterprise AI Governance
An effective enterprise AI strategy must prioritize responsible scaling. To build resilience and score highly on internal audits, organizations should structure their AI deployments around four core pillars:
1. Accountability
Every AI-generated recommendation or action must have a clear human owner. AI is excellent at assisting decision-making whether analyzing market trends or automating candidate evaluations for recruitment, but ultimate accountability must always remain with the people and the organization.
2. Governance
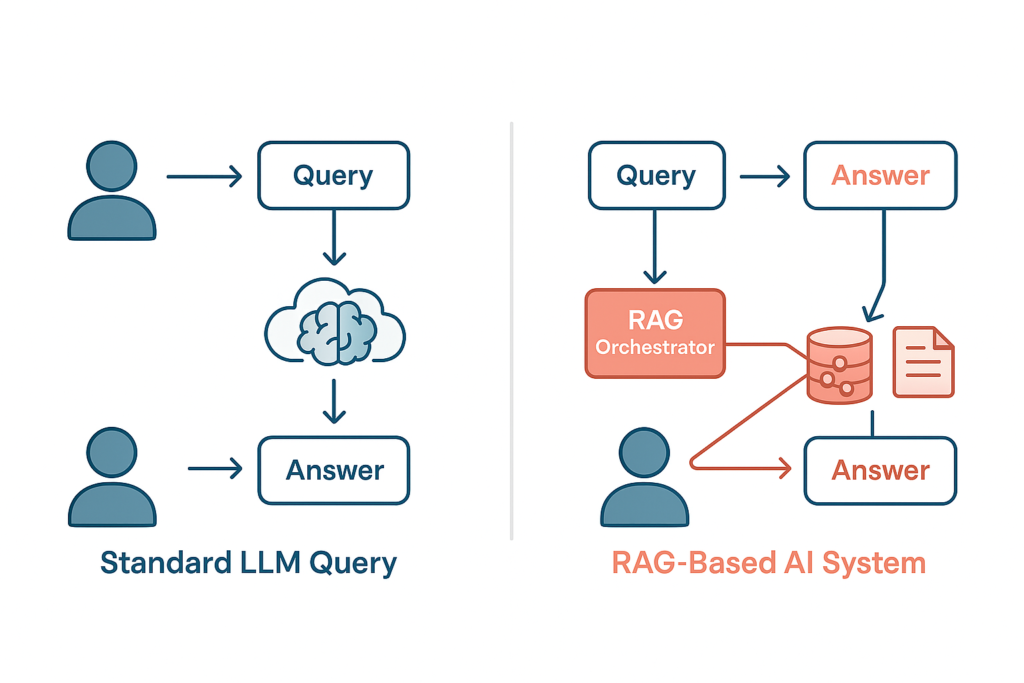
Every AI interaction should be traceable, explainable, and auditable. Enterprises need clear policies defining where AI can operate autonomously and where human approval is mandatory. Establishing structured quality assurance workflows ensures that AI outputs align with corporate standards over time.
For best practices on regulatory compliance, refer to the guidelines established by the IndiaAI Mission and NASSCOM’s responsible AI frameworks.
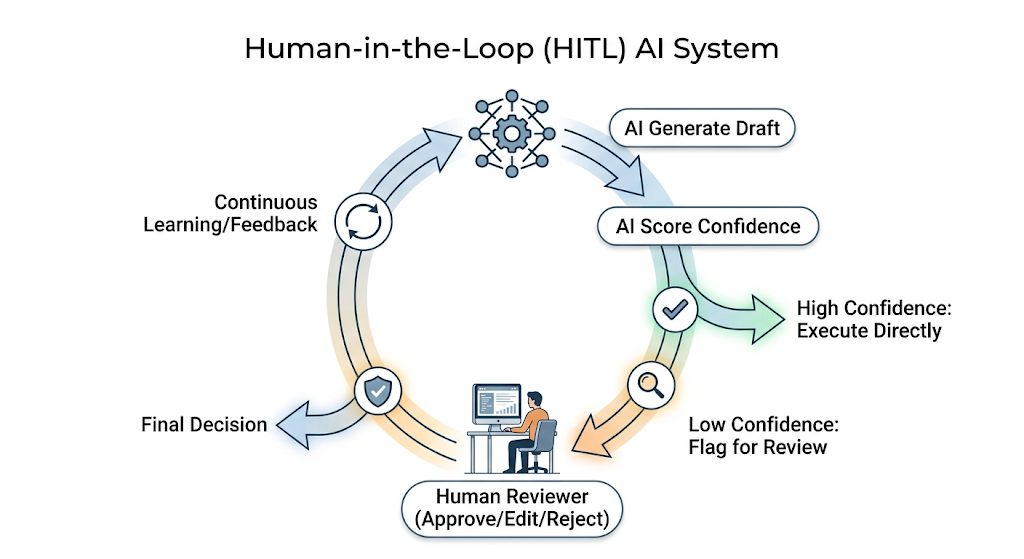
3. Human-in-the-Loop (HITL)
Not every decision should be automated. High-impact domains—such as healthcare, fintech, legal, and cybersecurity—require expert oversight before AI-driven actions are executed. The objective is not to replace human judgment but to augment it. Peer-to-peer communication and leadership coaching remain essential to ensure teams can critically evaluate AI outputs before they go live.
4. Resilience
AI systems should be designed with “graceful failure” in mind. If an AI model becomes unreliable, the business must continue operating through deterministic workflows, traditional software logic, or manual intervention. AI should enhance business continuity, not act as a single point of failure.
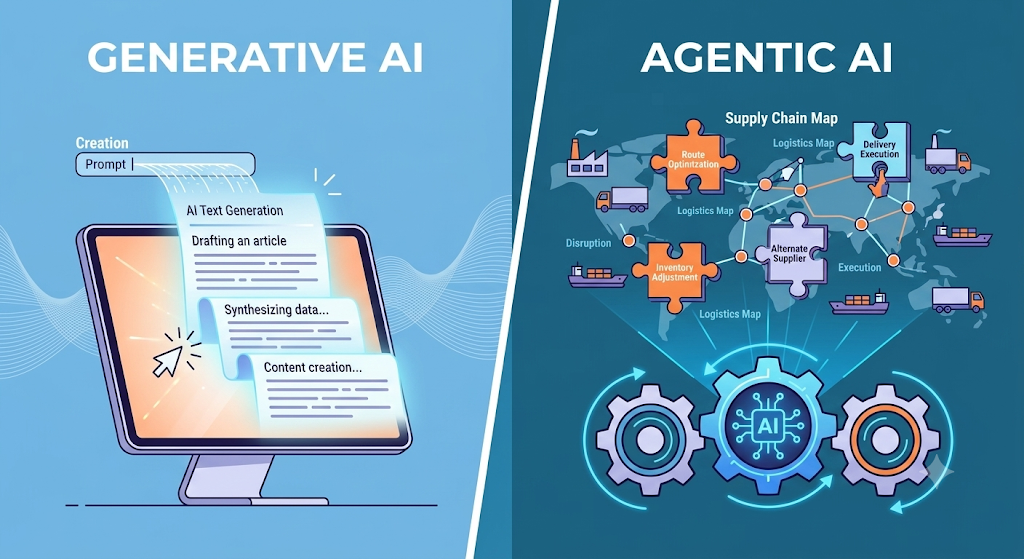
Agentic AI: Why Trust is the New Currency
The emergence of Autonomous and Agentic AI makes these principles even more critical. Autonomous systems can reason, plan, and execute tasks independently, such as coordinating external partner referral programs or managing onboarding compliance checks. However, increased autonomy directly increases organizational responsibility.
Trust cannot be built solely on model accuracy. It must be earned through rigorous governance to combat AI hallucinations in Indian enterprises, ensuring transparency and continuous validation across all automated workflows.
Building Resilient Enterprises for the Future
The next generation of enterprise AI platforms will not compete solely on intelligence. They will compete on trustworthiness. Organizations that invest today in AI governance, observability, and security will build resilient businesses capable of adapting as models evolve and technology changes.
Perhaps the future question for executives is not, “How much AI have we deployed?” Instead, it is, “Can our business continue to operate confidently when AI is uncertain?”
The enterprises that answer this question successfully will define the next era of digital transformation. AI is undoubtedly the future, but resilient enterprises will not be built on AI alone. They will be built on intelligent systems that know when to act, when to defer to humans, and how to recover when things go wrong. Because in the end, the most valuable AI will not be the one that makes the smartest decisions—it will be the one that businesses can trust.
Latest Blog Post – https://embarkingonvoyage.com/blogs/agentic-ai-enterprise-adoption/