

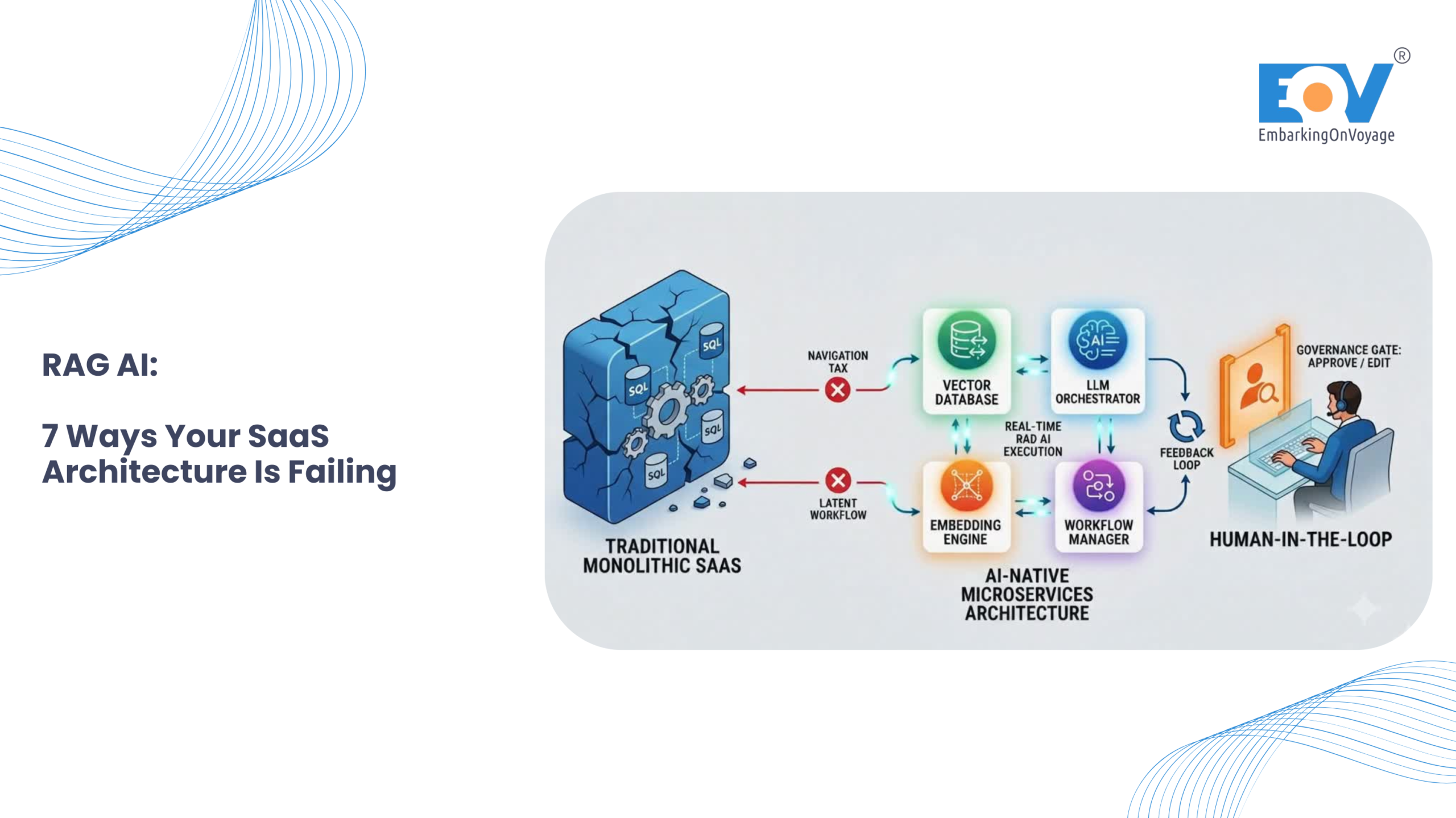
RAG AI is triggering a massive transformation in enterprise software. Over the last decade, traditional SaaS platforms were built around structured workflows, transactional databases, and REST APIs. Today, however, that legacy architecture is struggling to keep up with the demands of RAG AI systems.
But the rise of AI-native product development is changing software engineering completely. Today, enterprises are integrating AI copilots, intelligent search, autonomous workflows, contextual recommendation engines, and Retrieval-Augmented Generation (RAG) systems into their SaaS products.
This is exactly where traditional SaaS architecture begins to struggle.
What is RAG in AI-Native Product Development?
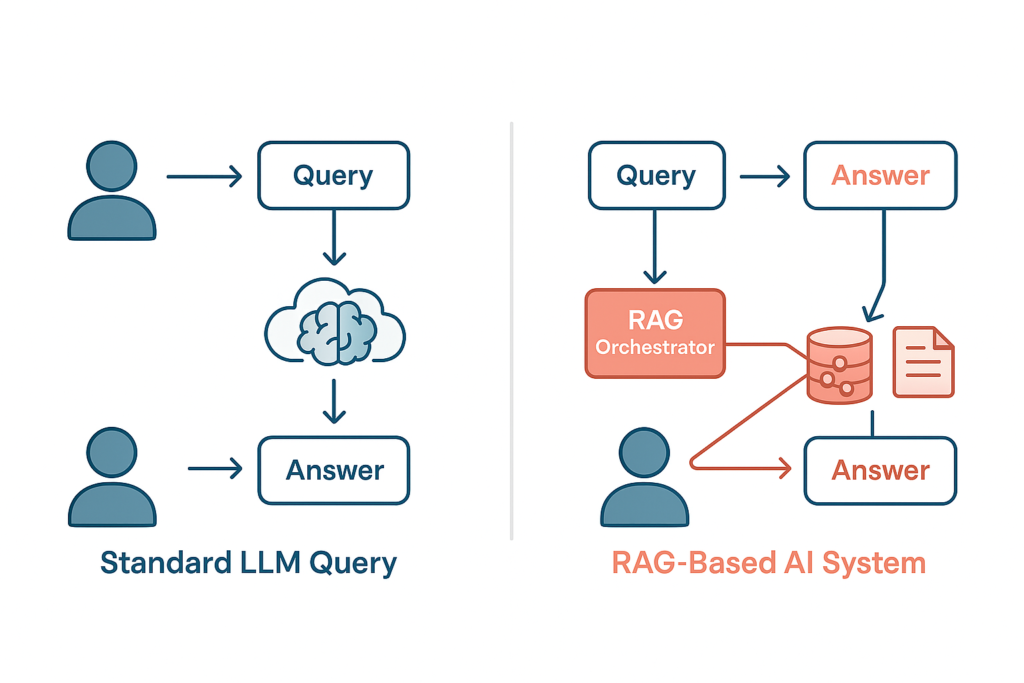
Retrieval-Augmented Generation (RAG) is an AI architecture pattern where enterprise data is retrieved in real-time before an LLM (Large Language Model) generates a response.
Instead of relying only on pre-trained knowledge, the AI retrieves:
- Enterprise documents and wikis
- Customer history and profiles
- Active workflows
- Operational records and logs
- Contextual business intelligence
By retrieving this exact data before generating answers, RAG dramatically improves contextual accuracy, enterprise intelligence, personalization, and overall AI reliability. RAG architecture is now becoming a foundational layer in AI-native SaaS platforms, agentic AI workflows, and intelligent automation tools.
Traditional SaaS Systems Were Built for Transactions, Not Intelligence
Traditional SaaS architecture focuses on structured databases, deterministic workflows, relational queries, and exact-match retrieval.
For example, a standard SQL query (SELECT * FROM Orders WHERE CustomerId = 1001) works perfectly in transactional environments. But RAG-based AI systems operate differently. AI-native applications require semantic search, contextual retrieval, embeddings, vector databases, orchestration pipelines, and dynamic AI inference.
If a customer asks an AI copilot, “Why was my refund request rejected?” the answer may exist across support tickets, internal policies, CRM notes, or workflow logs. Traditional keyword search often fails because enterprise intelligence is distributed. RAG solves this using semantic retrieval—and that is where legacy architecture starts breaking down.
Why Monolithic SaaS Architecture Fails Under AI Workloads
Most traditional SaaS products were designed as monolithic applications. Everything sits inside one ecosystem: APIs, business logic, authentication, reporting, workflows, and databases.
AI-native systems introduce completely different, heavy workloads. Now, the same platform must simultaneously handle:
- Vector search
- Embeddings generation
- LLM orchestration and prompt routing
- Retrieval pipelines
- Contextual reasoning
These workloads behave differently from traditional systems. Vector search requires high compute, embeddings need asynchronous processing, and LLM calls introduce external latency. As a result, monolithic SaaS systems experience scalability issues, latency bottlenecks, and rising operational costs.
As a result, monolithic SaaS systems experience scalability issues, latency bottlenecks, and rising operational costs when processing RAG AI workloads.
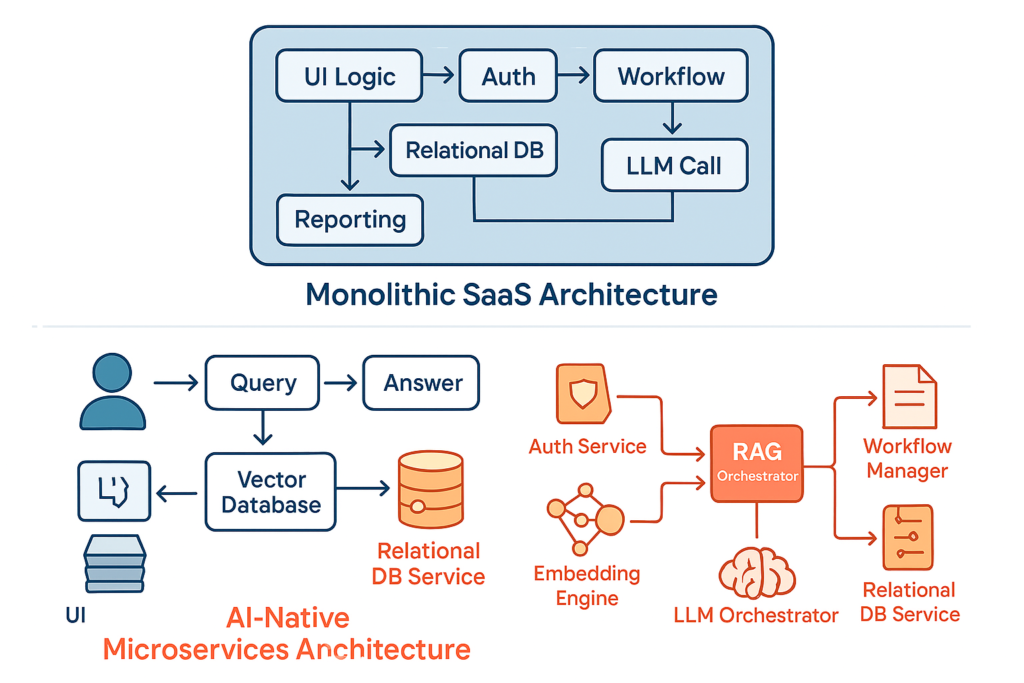
Traditional Databases Cannot Power Contextual AI
Relational databases like SQL Server, PostgreSQL, MySQL, and Oracle are excellent for structured enterprise data. However, RAG-based AI systems depend heavily on vector embeddings and semantic indexing.
This introduces the absolute need for vector databases, hybrid search architecture, and AI retrieval pipelines. Modern enterprise AI systems now use tools like Azure AI Search, Pinecone, Elasticsearch, Weaviate, or pgvector to support semantic AI search.
Without contextual retrieval, even powerful LLMs become disconnected from enterprise intelligence, which is why RAG AI requires specialized vector databases to function correctly.
Latency and AI Infrastructure Challenges
In traditional SaaS systems, response flows are highly predictable. But RAG-based AI workflows involve multiple complex steps before generating a final response:
- Semantic retrieval
- Vector search
- Reranking results
- AI orchestration
- Prompt engineering injection
- LLM inference
This introduces strict new requirements for latency optimization, caching strategies, AI observability, and infrastructure scaling. Most legacy SaaS products were never designed for this level of orchestration complexity.
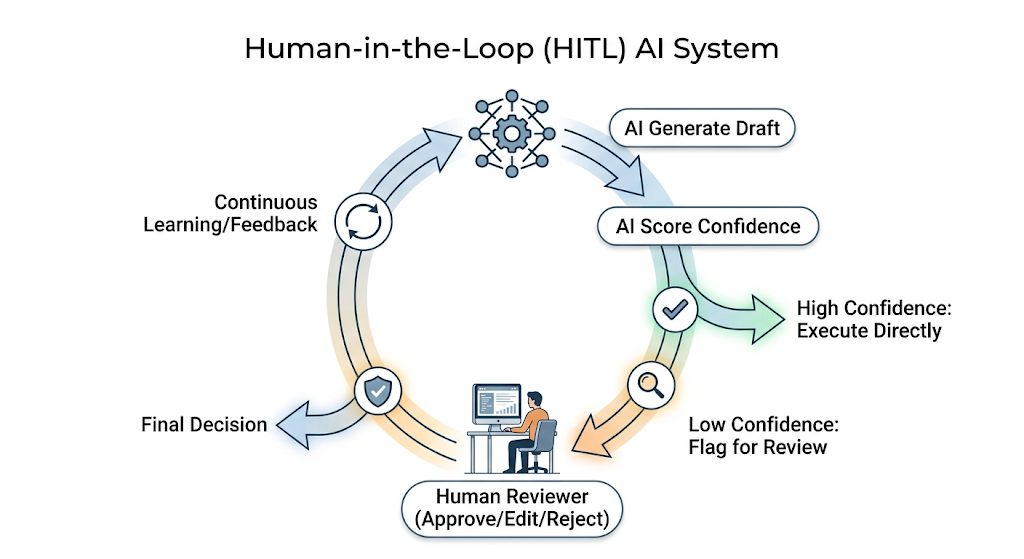
The Essential Role of Human-in-the-Loop Architecture
Enterprise AI systems cannot run entirely autonomously, especially in heavily regulated sectors like banking, healthcare, insurance, and travel platforms. Organizations increasingly require governance controls, approval workflows, audit trails, confidence scoring, and AI supervision.
This introduces Human-in-the-Loop architecture, where humans remain central to validating AI-driven decisions. Traditional SaaS systems rarely account for AI governance or contextual supervision, but AI-native systems must build these gates natively into the UI.
Final Thoughts: The Future is AI-Native
Traditional SaaS architecture is not outdated because it was poorly designed; it struggles because enterprise software expectations have fundamentally changed. Modern AI systems powered by RAG require contextual intelligence, semantic retrieval, scalable orchestration, and intelligent workflow automation.
“The future of enterprise software will belong to organizations that successfully combine AI-native product engineering with scalable RAG AI infrastructure.. Because successful AI systems are not just about generating text—they are about delivering trustworthy, scalable, and context-aware business intelligence.
Accelerate Your Enterprise AI Modernization Building robust RAG architectures requires moving beyond legacy monoliths. At EmbarkingOnVoyage, our digital product engineering teams specialize in integrating agentic AI, vector databases, and microservices into scalable, enterprise-grade applications.
References & Further Reading
To build truly scalable AI-native systems, we recommend consulting the following technical standards and architectural frameworks:
- Understanding the RAG Stack: A deep dive into the retrieval-augmented generation pipeline and how vector search integrates with LLMs.
- Microsoft Architectural Guidance: The RAG Pattern: Critical insights into the orchestration layers and infrastructure needed to support enterprise-grade AI workloads.
- AWS Primer on RAG: An authoritative explanation of the technical flow between enterprise data retrieval and generative inference.
- Martin Fowler on Microservices: Essential reading for understanding why modern AI-native applications require a shift from monolithic to distributed, event-driven architectures.
- The EU AI Act Official Portal: The primary reference for the governance, auditability, and “Human-in-the-Loop” requirements necessary for compliant enterprise AI deployments.
Latest Blog Highlight : https://embarkingonvoyage.com/blogs/best-ai-native-ui-ux-companies/
Visit our AI-Native Engineering Lab : https://embarkingonvoyage.com/ai-native-engineering-lab/
Leave a Reply